
About
"An endangered language will progress if its speakers can make use of electronic technology."
— David Crystal (Language Death, p. 13)
Languages in the Middle East
The western part of Asia, known as the Middle East or Near East, is a linguistically diverse region crucial for geopolitical and economic reasons. Home to over 300 million people speaking more than 30 languages from various language families, this area faces significant linguistic challenges (As if the region needed more complexity to spice things up!). Many languages, particularly those in Turkey, Syria, Iran, and Iraq, suffer from discrimination and neglect, impacting their usage and preservation. On the other hand, advancements in language technology have focused on prominent regional languages such as Arabic, Hebrew, Persian, and Turkish, while numerous other languages in the area have received little attention or development.
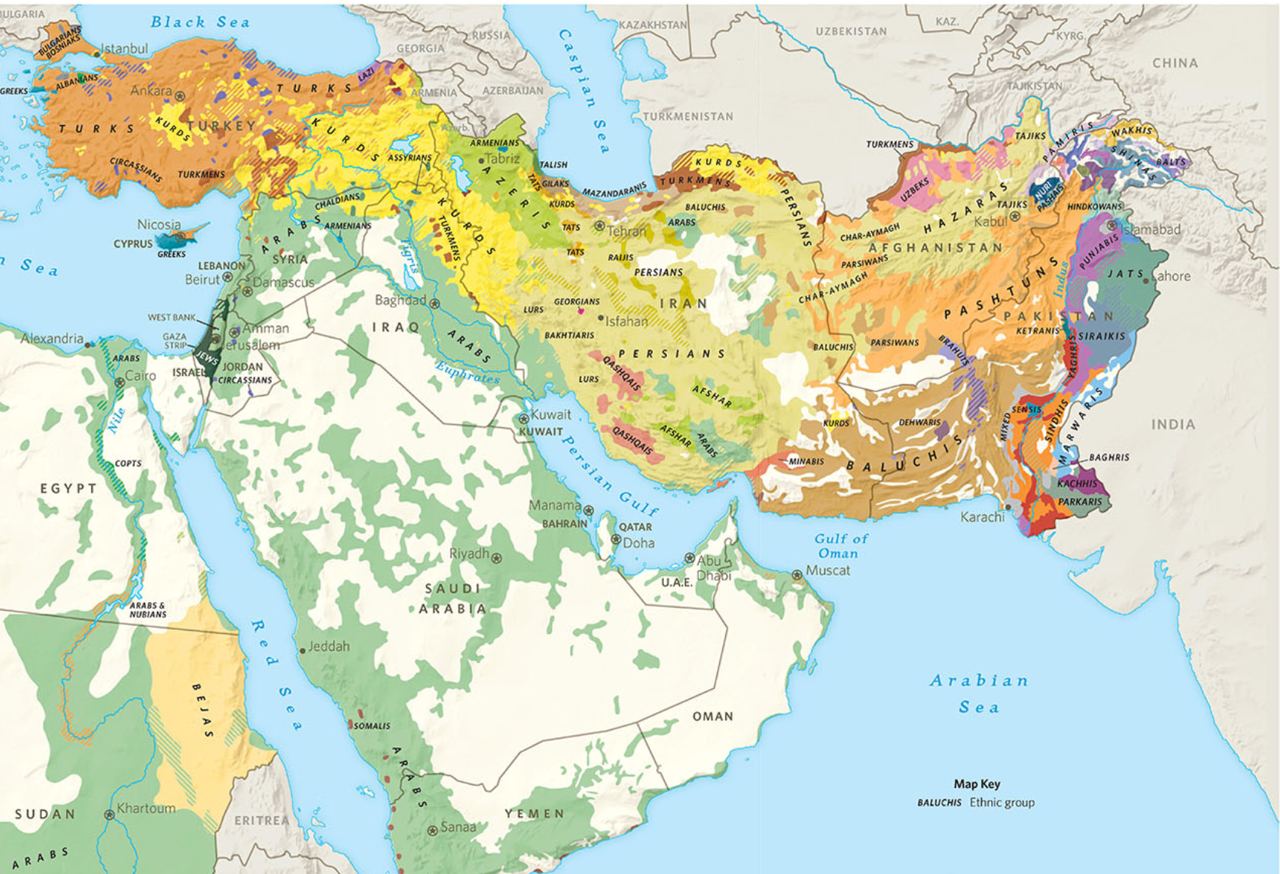
Digitally disadvantaged languages
The target languages face significant digital challenges due to their lack of standardization and official support. Most are primarily spoken rather than written, and when written, they often use scripts of administratively dominant languages like Turkish or Persian. This inconsistency in writing systems complicates language identification and hampers data-driven approaches due to data scarcity. The absence of conventional orthographies and the use of various scripts (Latin, Arabic) create confusion and impede the development of language processing tools. Consequently, these languages lack basic digital resources such as keyboards, fonts, and OCR systems. The digital divide extends to social media, online education, and information access, further marginalizing speakers and potentially accelerating language decline. Addressing these issues is crucial for ensuring these languages’ survival and relevance in the digital era.
Language empowerment through technology
DOLMA-NLP is a community-driven project dedicated to advancing natural language processing for underrepresented languages in the Middle East. The project focuses on creating language technology, particularly machine translation, for several languages, including Zazaki, Gorani, Mazanderani, Talysh, Gilaki, Laki, and Luri. These languages, with speaker populations ranging from 250,000 to 5 million, represent a crucial yet underserved linguistic group. By developing resources for these languages, we aim to catalyze progress in language technology and machine translation, addressing a critical gap in the region’s linguistic landscape.
By developing digital resources and tools, we’ll enable these communities to use their languages more easily in everyday technology, from smartphones to online platforms. This increased digital presence will elevate the languages’ prestige and raise awareness among speakers about the importance of language preservation and active use. Moreover, our work will benefit researchers and developers working on related languages, fostering a ripple effect of linguistic empowerment in the region. Ultimately, this project contributes to preserving cultural diversity and promoting linguistic rights in the digital age.
Objectives
1. Solving problems
We plan to leverage the created resources to expand NLP applications for the target languages. Most importantly, this includes developing machine translation, language identification models and also, text transliteration tools. To measure impact, we’ll track the adoption of our tools within the speaker communities and gather feedback to guide future developments. Long-term goals include creating comprehensive language processing applications and contributing to digital language documentation efforts.

2. Open-source development
As an advocate for open-source research, I will ensure wide dissemination of our project outcomes. All resources, including corpora, tools, and models, will be released on GitHub. This approach allows for easy access and encourages further development by the research community.

3. Creating NLP communities
This project relies on the contributions of enthusiastic language speakers. To ensure our work reaches and benefits the speaker communities, we’ll collaborate with local organizations and use social media to share user-friendly guides and resources in the target languages. This multi-faceted dissemination strategy will maximize the impact and accessibility of our work.

Join us!
We seek collaborations with language enthusiasts, academic institutions and tech companies to scale up our efforts focused on language preservation and technological innovation. Please contact us.