
Languages in the Middle East
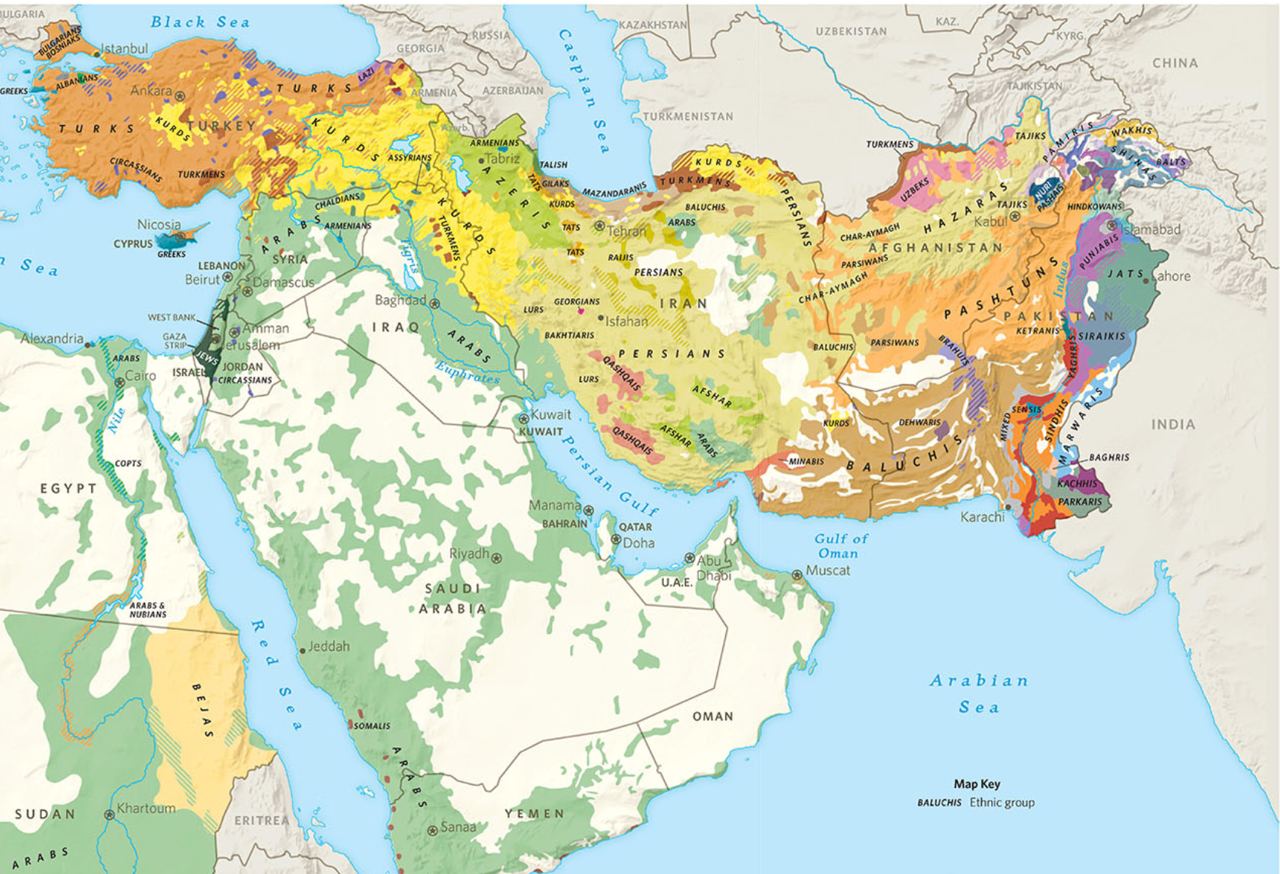
The western part of Asia, known as the Middle East or Near East, is a linguistically diverse region crucial for geopolitical and economic reasons. Home to over 300 million people speaking more than 30 languages from various language families, this area faces significant linguistic challenges (As if the region needed more complexity to spice things up!). Many languages, particularly those in Turkey, Syria, Iran, and Iraq, suffer from discrimination and neglect, impacting their usage and preservation. On the other hand, advancements in language technology have focused on prominent regional languages such as Arabic, Hebrew, Persian, and Turkish, while numerous other languages in the area have received little attention or development.
Why DOLMA-NLP?
Our project focuses on creating parallel corpora and developing language technology for several languages in the Middle East, such as Zazaki, Gorani, Southern Kurdish, Mazanderani, Gilaki, Laki, and Luri. These languages, with speaker populations ranging from 250,000 to 5 million, represent a crucial yet underserved linguistic group. By developing resources for these languages, we can catalyze progress in language technology and machine translation, addressing a critical gap in the region's linguistic landscape.
DOLMA stands for "Developing Technologies for Middle Eastern Languages". While it shares its name with the delicious stuffed grape leaves dish, our DOLMA is filled with passion and enthusiasm for language digitalization, as well as respect and love for language communities across the Middle East. Our mission transcends ethnic differences and geopolitical divisions, uniting the region through the power of language technology.
Updates
- PARME Paper Recognized as Outstanding at ACL 2025 🏆 - August 1, 2025
- DOLMA-NLP Joins Meta's Language Technology Partner Program to Advance Middle Eastern Language Technologies 🎉 - May 15, 2025
- Community-Driven ASR: Creating Speech Recognition for Low-Resource Middle Eastern Languages - May 5, 2025
- Why Open-Source is the Lifeline for Low-Resourced Languages in the AI Era - April 1, 2025
- From Endangered to Empowered: Our Journey Building Language and Speech Technologies for Middle Eastern Languages - March 6, 2025
- Exciting News: DOLMA-NLP is accepted to the SILICON Practitioners Program 🎉 - August 12, 2024
- August 1st, 2024: Our website is live!